Adaboost를 공부할 겸 처음부터 구현해 보았다.
기록 용으로 코딩, 결과, 핵심 alpha 유도 과정을 남겨 둔다.
핵심 포인트:
AdaBoost는 동전 던지기에서 앞이 나올 확률(50%보다) 약간 높은 Weak Classifier를 여럿 조합하여
강력한 모델을 만든다.
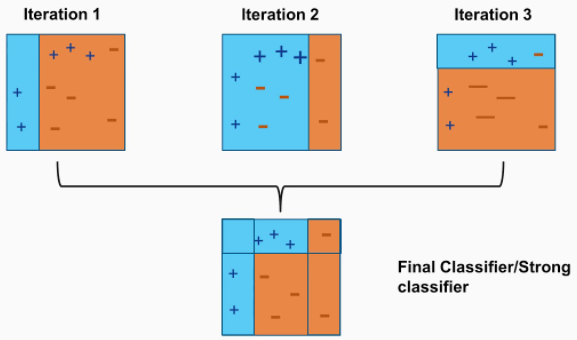
그림을 보면 Weak Learner는 Iteration1, Iteration2, Iteration 3 밑에 있는 모델이다.
Iteration 1은 파란색 3개를 잘못 분류했다.
Iteration 2는 빨간색 3개를 잘못 분류했다.
Iteration 3은 파란색 2개를, 빨간색 1개를 잘못 분류했다.
하지만 세 모델을 결합하면 하나도 틀리지 않고 분류한다.
0.42, 0.65, 0.92가 alpha 값이다.
각 모델을 0.42 * 모델1 + 0.65 * 모델2 + 0.92 * 모델3으로 조합한다.
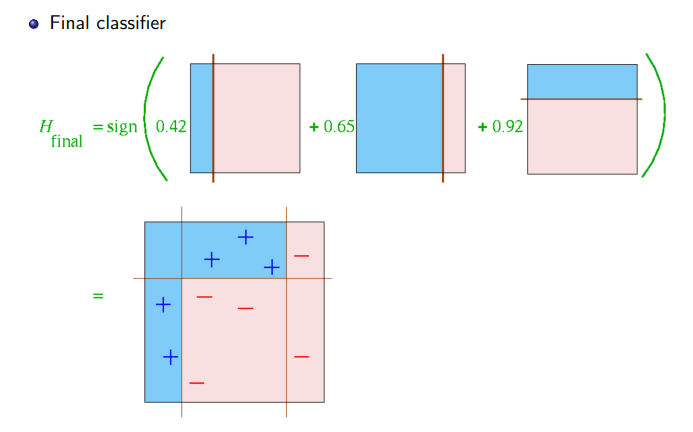
alpha 값이 중요한데, alpha 값은 각 Classifier(Weak Learner)의 분별력을 의미한다.
alpha 값은 log((1-error) / error) 이다
이때 이론적으로 ADABoost의 training loss를 최소화 할 수 있다.




>>결과

>>코딩
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
|
import numpy
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
########################################################################
################### ADABoost를 위한 Utility 정의 ######################
########################################################################
class Utility:
@staticmethod
def compute_error(y: numpy.array, y_pred: numpy.array, w_i: numpy.array) -> numpy.array:
'''
y -> numpy.array: 정답
y_pred -> numpy.array : 예측값
w_i -> numpy.array : 각 관측값에 대한 계수
'''
return (numpy.sum((w_i * numpy.not_equal(y, y_pred)), axis=-1).astype(int)) / numpy.sum(w_i)
@staticmethod
def compute_alpha(error: numpy.array) -> numpy.array:
return numpy.log((1-error+1e-6)/(error+1e-6))
@staticmethod
def update_weights(w_i: numpy.array, alpha: numpy.array, y: numpy.array, y_pred: numpy.array) -> numpy.array:
w_i_updated = numpy.where(numpy.not_equal(y, y_pred),
w_i * numpy.exp(alpha * (numpy.not_equal(y, y_pred))),
w_i * numpy.exp(-alpha * (numpy.equal(y, y_pred))))
w_i_updated = w_i_updated / numpy.sum(w_i_updated)
return w_i_updated
########################################################################
################### ADABoost Class 정의 ################################
########################################################################
class AdaBoost:
def __init__(self):
self.alphas = []
self.G_M = []
self.M = None
self.training_errors = []
self.prediction_erros = []
def fit(self, X: numpy.array, y: numpy.array, M: int = 150) -> None:
'''
AdaBoost 모델 Fitting
Arguments:
X -> numpy.array: 트레인할 변수들
y -> numpy.array: 정답
M: Boosting 할 횟수, Weak learner의 개수
'''
self.M = M
for m in range(0, M):
if m == 0: # 최초 부스팅 시작
w_i = numpy.array(numpy.ones(len(y))) / len(y)# Weight 초기화
else:
w_i = Utility.update_weights(w_i, alpha_m, y, y_pred)
# Weak Classifier 생성
G_m = DecisionTreeClassifier(max_depth = 1) # Stump 생성
if m == 0:
G_m.fit(X, y, sample_weight = w_i.astype(float))
else:
G_m.fit(X, y, sample_weight = w_i)
y_pred = G_m.predict(X)
# Weak Classifier 저장
self.G_M.append(G_m)
error_m = Utility.compute_error(y, y_pred, w_i)
self.training_errors.append(error_m)
# Alpha 계산
alpha_m = Utility.compute_alpha(error_m)
self.alphas.append(alpha_m)
assert len(self.G_M) == len(self.alphas)
def predict(self, X: numpy.array) -> numpy.array:
'''
타겟값 예측
X -> numpy.array : 예측할 변수들
'''
weak_preds = numpy.zeros(shape = (X.shape[0], len(self.G_M)))
for i,m in enumerate(range(self.M)):
y_pred_m = self.G_M[m].predict(X).astype(float)*self.alphas[m]
weak_preds[:, m] = y_pred_m
y_pred = numpy.sign(numpy.sum(weak_preds, axis=-1))
return y_pred
########################################################################
############################ Data Load #################################
########################################################################
data = load_breast_cancer()
X = data.data
X = X.astype(float)
y = numpy.where(data.target==0, -1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
########################################################################
################ AdaBoost Train ########################################
########################################################################
accuracies = []
for len_weak_learner in range(5,100):
ada = AdaBoost()
ada.fit(X_train, y_train, M=len_weak_learner)
y_pred = ada.predict(X_test)
accuracy = (y_pred==y_test).sum() / len(y_test)
accuracies.append(accuracy)
########################################################################
########################### Result Plot ################################
########################################################################
plt.title("Accuracy by Increasing the number of Weak Learners")
plt.plot(accuracies)
plt.xlabel("Weak Learner number")
plt.ylabel("Accuracy")
plt.show()
|
'머신러닝' 카테고리의 다른 글
| 링크, google landmark recognition 설명 (0) | 2021.08.22 |
|---|---|
| 공부기록 - Optimal Bayesian Rule (0) | 2021.06.16 |
| 파이썬 Gradient Boosting 바닥부터 구현하기 (0) | 2021.06.11 |
| Bias Variance Decomposition and XGBOOST와 RANDOMFOREST 주의사항 (0) | 2021.06.10 |
| 파이썬 VIT - Vision Transformer 텐서플로우 코랩 구현 (2) | 2021.06.06 |



