CPU와 GPU에서의 연산 속도 비교하기
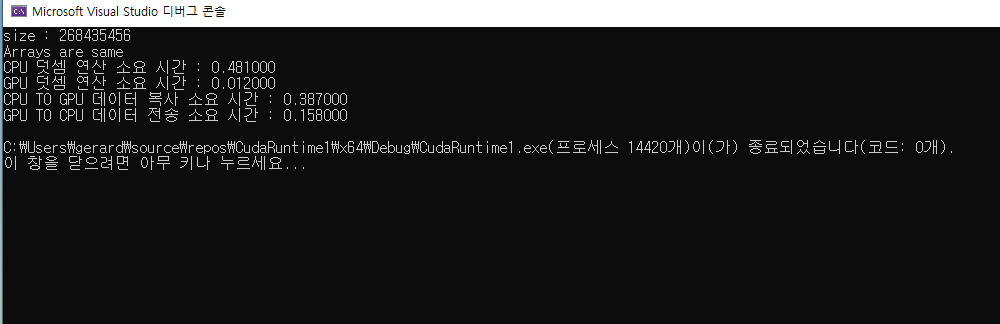
GPU에서의 속도가 400배 이상 빠르다.
덧셈 연산에서 인텔 I7 CPU에 비해 RTX 2070 super 가 400배 이상 빠름을 알 수 있다.
코드 >>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
|
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdlib.h>
#include <cstring>
#include <time.h>
#include <stdio.h>
#include <iostream>
#define gpuErrchk(ans) { gpuAssert(ans, __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char* file, int line, bool abort = true)
{
if (code != cudaSuccess)
{
printf("Error 발생!\n");
fprintf(stderr, "GPU 에러: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
void sum_array_cpu(int* a, int* b, int* c, int size)
{
for (int i = 0; i < size; i++)
{
c[i] = a[i] + b[i];
}
}
__global__ void sum_array_gpu(int* a, int* b, int * c, int size)
{
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < size)
{
c[gid] = a[gid] + b[gid];
}
}
void compare_arrays(int* a, int* b, int size)
{
for (int i = 0; i < size; i++)
{
if (a[i] != b[i])
{
printf("a[i] : %d, b[i] : %d\n", a[i], b[i]);
printf("다른 배열!\n");
return;
}
}
printf("같은 배열 \n");
}
int main()
{
int size = 1 << 28;
printf("size : %d\n", size);
int block_size = 1024;
int NO_BYTES = size * sizeof(int);
int* h_a, * h_b, * gpu_results, * h_c;
if ((h_a = (int*)malloc(NO_BYTES)) == NULL ||
(h_b = (int*)malloc(NO_BYTES)) == NULL ||
(h_c = (int*)malloc(NO_BYTES)) == NULL ||
(gpu_results = (int*)malloc(NO_BYTES)) == NULL)
{
fprintf(stderr, "메모리 부족 !");
exit(EXIT_FAILURE);
}
time_t t;
srand((unsigned)time(&t));
for (int i = 0; i < size; i++)
{
h_a[i] = (int)(rand() & 0xFF);
}
for (int i = 0; i < size; i++)
{
h_b[i] = (int)(rand() & 0xFF);
}
memset(h_c, 0, NO_BYTES);
memset(gpu_results, 0, NO_BYTES);
int* d_a, * d_b, * d_c;
gpuErrchk(cudaMalloc((int**)&d_a, NO_BYTES));
gpuErrchk(cudaMalloc((int**)&d_b, NO_BYTES));
gpuErrchk(cudaMalloc((int**)&d_c, NO_BYTES));
/////////////////////////////////////////////////
// CPU에서 GPU로 데이터가 복사되는 시간을 측정 //
/////////////////////////////////////////////////
clock_t htod_start, htod_end;
htod_start = clock();
cudaMemcpy(d_a, h_a, NO_BYTES, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, NO_BYTES, cudaMemcpyHostToDevice);
htod_end = clock();
dim3 block(block_size);
dim3 grid(size / block.x + 1);
////////////////////////////////////////////////////
// CPU에서 덧셈 연산을 하는데 걸리는 시간을 측정 //
///////////////////////////////////////////////////
clock_t cpu_start, cpu_end;
cpu_start = clock();
sum_array_cpu(h_a, h_b, h_c, size);
cpu_end = clock();
////////////////////////////////////////////////////
// GPU에서 덧셈 연산을 하는데 걸리는 시간을 측정 //
///////////////////////////////////////////////////
clock_t gpu_start, gpu_end;
gpu_start = clock();
sum_array_gpu << <grid, block >> > (d_a, d_b, d_c, size);
cudaDeviceSynchronize();
gpu_end = clock();
/////////////////////////////////////////////////////////////////////////
// GPU에서 덧셈 연산 이후 CPU에 데이터를 전송하는데 걸리는 시간을 측정 //
/////////////////////////////////////////////////////////////////////////
clock_t dtoh_start, dtoh_end;
dtoh_start = clock();
cudaMemcpy(gpu_results, d_c, NO_BYTES, cudaMemcpyDeviceToHost);
dtoh_end = clock();
//array comparison
compare_arrays(gpu_results, h_c, size);
printf("CPU 덧셈 연산 소요 시간 : %4.6f \n",
(double)((double)(cpu_end - cpu_start) / CLOCKS_PER_SEC));
printf("GPU 덧셈 연산 소요 시간 : %4.6f \n",
(double)((double)(gpu_end - gpu_start) / CLOCKS_PER_SEC));
printf("CPU TO GPU 데이터 복사 소요 시간 : %4.6f \n",
(double)((double)(htod_end - htod_start) / CLOCKS_PER_SEC));
printf("GPU TO CPU 데이터 전송 소요 시간 : %4.6f \n",
(double)((double)(dtoh_end - dtoh_start) / CLOCKS_PER_SEC));
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_a);
free(h_b);
free(h_c);
free(gpu_results);
return 0;
}
|
'Cuda' 카테고리의 다른 글
| C++ CUDA Warp 발산 (0) | 2021.05.31 |
|---|---|
| C++ Cuda 시스템 정보, GPU 정보 불러오기 (0) | 2021.05.31 |
| C++ Cuda 메모리 할당에서의 예외 처리 (0) | 2021.05.30 |
| C++ Cuda GPU에서의 더하기 연산 (0) | 2021.05.30 |
| C++ CUDA 문제 2. CPU에서 GPU로 데이터를 전달하여 3차원 공간에서 병렬 실행하기 (0) | 2021.05.30 |

